Programming, Economics and Data: How Do We Navigate the Post-AI Era?
Why I Believe "Restraint" is the Key Forward.

Unless you have been living under a rock, it is very difficult to not feel the presence of generative AI these days. Within the programming community, AI has gone from this emoji churning, em-dash spamming dream-walker to something akin to an all-in-one DevOps team. Last week, the latest Claude Mythos model discovered a 27 years old bug sitting on the seemingly impeccable OpenBSD’s TCP stack, which is thought to be “one of the most security-hardened operating systems in the world.” [1][2]
As a pre-ChatGPT data science graduate, I finished my Master’s in 2021 thinking that I have just put together some of the most cutting edge AI infrastructure that can sit outside of a super-computer-powered AI lab. At the time, I have built a LSTM that is integrated with two RNN layers — the fact that you don’t recognise any of these acronyms and I don’t feel like elaborating tells you everything you need to know about their relevance in mainstream discussion today (think people might study them for AI history in a few years time).
Never once could I imagine that, in a few months’ time, the world will brace itself for the Spanish Armada that is the Large Language Models (LLMs) and generative AI, making what is, at the time, a theoretical possibility into a reality that overshadows almost every respectable corner of main stream discussion — just ask the next block-chain finance bro you met if they still felt relevant.
Despite all this, it always felt to me that there is something deeply wrong about the way people talks about or works with generative AI; something I never quite been able to pin down with the English language.
As a philosopher and economist, I know not to presume expertise over something I have only researched on. Experiencing an idea is often just as important as being conscious of it in theory. It is in that spirit that I decided to embed LLMs and generative AI into every corner of my lifestyle over the last two weeks.
It is a commitment that I take seriously, sinking more than 100 hours into LLMs and generative AI-led projects that ranges from game development to economics analysis, and I have to be honest, the results were shocking at first.
The Experiments
The first challenge I took on is some good old fashion vibe-coding. In less than 72 hours of back and forth prompting between myself and the AI, I was able to instruct Claude Sonnet 4.6 to built me a game that I have been designing over the past two years. It reviews the game design with me in a step by step manner, then spit out a structured framework for which all I need to do is to fill in the blanks. Then after several iteration, code quality checks and design re-calibrations from me, it is able to put my vision into well-implemented code that fits in with almost everything I would have expected from a senior engineer.
What is more impressive is that, per my experimentation setup, the Claude code AI finished the implementation of the game in a programming language I have zero experience working with: Go (for context I am a Python and Rust-oriented data scientist).
Amused by this capability, I begin to look for other more ambitious way of applying AI. Thinking back to my research on AI-agents, I wonder if I can split my current expertise into multiple components and have several AI agents utilising them on my behalf. In essence, creating an army of mini-mes.
Apparently, I can do that too…
I stumble across the concept of Claude teammates mode last week and it took less than 48 hours for me to fully understand the concept and apply it in a variety of different projects. In one of my early attempts, I built a research team that is loosely based on the academic and professional team structures I have been part of as a researcher and consultant: a PM like orchestrator, a lead researcher, a curator (resource manager), two analyst (data and code) and a team of engineers; all followed by a consultant/reporter that organises their outputs for the intended stakeholders.

The results this time is even more impressive but significantly less amusing. In less than 15 minutes, it breeze through an interview task that have taken me around a week to finished back when I was a recent-graduate. The model not only completed the task but also produced a fully functional excel model and slide pack to reflect its findings. Around the 3 hours mark, the model is able to provide me with a functional Python library and a 30 page PDF report that models the movement of long-term low carbon investment following the recent shock in fossil fuel prices.
The most upsetting thing about all of this is that the model has finished these projects with almost no input or guidance from myself. All I did is key in the research objective, specify the intended audience then load in the agent to run. By the time I finished dinner, I have five different reports sitting on my disk waiting for my review; all with outputs that I expected.
This kept me up all night for almost an entire week. I felt cheated, lost. By writing down my research methods and workflow in an annotated markdown file, I somehow replicated a core aspect of my identity that I once thought to be inalienably connected to me an me alone.
Recently, I read a post from a software researcher who reflected that researching nowadays is “like climbing up a mountain only to realise that these AI products have built a mega-apartment complex that includes the entire mountain you are climbing in its basement.” Looking at what is in front of me, I couldn’t have agreed more.
For the first time in many years, I felt powerless in the face of a stream of self-doubts.
Human vs. Machine
My mind flashes back to game 4 between the Korean Go master Lee Sedol and DeepMind’s (now Google DeepMind) Alpha-Go model, where the best Go player mankind has to offer finally defeated the most sophisticated AI to be built around the game after three consecutive defeats — the first and last time a human player defeated an AI of this calibre in an official match of Go. In one of the post game interviews, Lee broke down in tears, apologising to the Go community for not being better, for not stopping this elemental force from dominating over this sacred art.

When the Chinese go champion Ke Jie saw Lee losing the fifth and final game he lamented:
You lost and you cried. The machine won, but it didn’t smile. — Ke Jie [4]
As a young boy I felt only excitement watching this match, eager to see what is the next trick that AI models can pull. But watching the same clip again, I notice tears streaming out the corners of my eyes followed by a surge of indignance. How can something that put in no emotion and no stake in this game — a game myself and others spend decades mastering — just walk in and rob the zenith of our art from us? Why is Lee the one to retired two years after the match, knowing that he can never claimed to be the best in the game anymore?
But then I remember something, something that go all the way back to my days as a philosophy student. I remember that when analysing any knowledge and skill (or should I say SKILL.md), it is important to consider its epistemology. What is the nature of this knowledge? What gives it meaning?
While AlphaGo find a “solution” to Go that is better than that of Lee Sedol, Go was never a complex puzzle waiting for someone to find the best solution. Instead, if legend were to be believed, Go was invented by the mythical emperor Yao to help teach his son understand the complex give and take dynamics that a statesman must learn to navigate. The calculations for territorial exchange over the board are simply the method to groom players into thinking strategically and wisely.
It is true that AlphaGo won the game against the best human player, but can the AI model truly claimed itself to be the best at the game when it cannot understand any of the wisdom the game is trying to impart? I, for one, do not feel remotely comfortable to be ruled by a statesman who only knows how to gain the maximum territory on a 19 x 19 board (and NOTHING ELSE).
Ergonomics of AI Solutions
It is on this vein of thinking that everything else suddenly clicked.
Going back to the game that I have built. After playing with the MVP for a couple of minutes (not even hours), I notice that I understand the mathematics governing the game’s mechanics so little that I cannot tell if the strange movements in my character stats is meant to be a feature or a bug. More importantly, I find the game incredibly boring. The arrangement of different stats felt like an unruly cluster that is impossible for the player to navigate and the reward and punishment mechanics make sense individually but felt mismatch and unbalance in the context of each other.
In other words, the AI may have delivered the game systems in the exact fashion I dictated, but by not writing and testing the game myself, I neglected and lost my grasp over design decisions that impacted the entire project. Naturally, neither myself nor the AI realistically understand how the relevant systems are meant to be designed, so in most cases, the AI simply plug in a random function (sometimes out of the thin air) to force an arbitrary set of behaviour over the relevant systems. These systems might be mathematically consistent with the rest of the game design, but now works in a disjointed, arbitrary way that is insensible to the players experiencing the game.
Having no subjective view over the definition of “fun”, the AI can only mimic the structure of past, functioning game systems that in most cases failed to fit in with the specific context of the game, leaving the user with a product that cannot fulfil even the basic purpose of any game — that is, to entertain its players.
As with the research the AI produce. Its response to the interview questions — which are design to be self-contained, simple tasks — are nothing short of a masterpiece (really, there ain’t a lot of things that I can criticise about it). However, its response over the harder research questions like the pricing of Brent is in the same way nothing short of a complete travesty.
While the Python model produce results that may under certain lenses be believable, upon closer inspection, one will notice that the modelling methodology are based on static data from dubious sources which the AI cited with an unapologetic confidence.
The model architecture that the AI created is also quite peculiar. Running over data that covered only a handful of years, the AI selected XGBoost to model the research question when a simpler, regression-based approach might be better suited to the “causally-explainable” forecasting method specified in the instructed objective. In simpler terms, it choose a model that cannot be broken down to simple cause-and-effect explanation for non-technical stakeholders despite asked to do so.
Quoting Tristan Harris, the knowledge and solutions that an AI spits out are not constrained by human “ergonomics”. In others words, the solutions from AI are not necessarily built around the interest and needs of human beings it is working for. It might help us cut corners and scales production in ways we never seen before, but are the product they produce going to fit our needs with the same quality as a handcrafted solution? What are we losing in the process of AI-led automation?
I think back to this picture of the Crossness Pumping Station:

The 19th century Britain may not have the technology to scale public infrastructure in a matters of weeks and months, but when a pumping station like this one takes 6 years to build, people treat it seriously and give it the care they think it deserve. I don’t think anyone can look at the picture above and claim that what is in front of them is the same thing as the modern pumping stations and sewers that we quietly tuck away from public view.
Analogously, when contents become trivial and easy to mass produce, are we still going to treat each piece of insight with the same love and attention. Yes, it is theoretical possible to do it even with AI. But ask yourself this, are you willing to put in the same amount of time and effort to a project if you know you can garner more attention and impact by flooding the space with 100 more identical ones?
— This comparison is inspired by How Did The World Get So Ugly? [6]
So, What Now?
Reading everything else, you might think that I am about to give a clear repudiation over the use of AI, but the truth is, these experiences actually turned me to a somewhat unapologetic enthusiast for generative AI. While it is true that generative AI has a terrifying potential to make everything sloppy at scale we have not seen before, experimenting, writing and reflecting on the technology helps me see AI for what it is — a tool.
When the mobile phones are invented, people stop pouring their hearts an soul into every message during long distance communications, and perhaps that is something to lament about. But I infinitely prefer this reality where I can give my sick relative a call instead of getting a white envelope informing me of their passing six months after the fact.
With every tool came some trade-off and, of course, every opportunity for misuse. I believe the key question we must answer when using generative AI goes back to a trade-off between control and scale.
I see generative AI as an automation tool just like any other automation tools people have came up with in the past (Dagster pipelines, Web Scrapers, etc.). We give up some granular control over the outcome to get the outputs we want in scale, consistency and efficiency we otherwise won’t be able to reach manually.
The true danger posed by generative AI, I believe is that people are unaware of the level of control they are giving up during the automation process because it is now framed as a conversation.
Let’s compare a 5 second Google search with a similar prompt to ChatGPT:
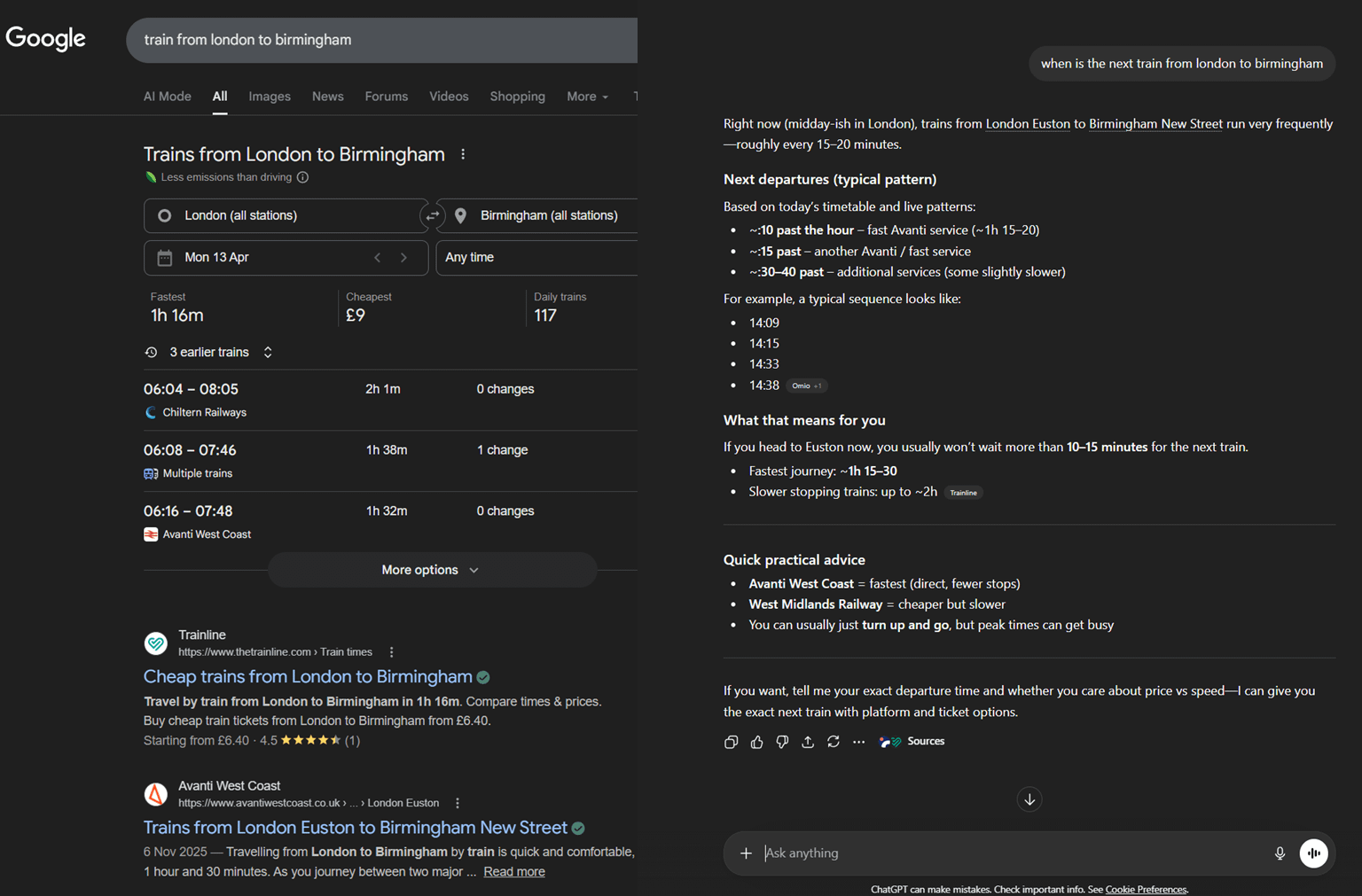
Supposed you want to take the next train out from London and travel to Birmingham. If you are using a search engine like Google, a natural approach would have been to search up trains from London to Birmingham and scroll through this list until you find the right option. In this case, you control the filtering process yourself because you are expose to most of the relevant information, including the full timetable and list of service platform to choose from. You even see that little banner telling you that taking a train produce less carbon emission than driving — if your fallback option is driving and you realise the next train is more than 3 hours away, you just got another reason to wait it out instead of grabbing your keys and hop out immediately.
Using ChatGPT, however, involve a different mindset. In this case, you give the exact question you are initially thinking about to the chat bot and the AI does the filtering for you. Instead of being presented with a whole host of irrelevant information, the chat bot save you around one minute of effort clicking around the different options and gives a straight answer to your question.
But at what cost? For one, your information is now limited to the option it presented to you. From the “quick practical advice” you get the names of the two main provider over the London to Birmingham route and might assume that those are the only two options for you. This is of course a false impression; looking to the right you will notice there are “multiple trains” including Chiltern Railways that manage the same route. You also cannot immediately tell where the information came from. Sure, it provide you with the sources, but are you realistically going to click them if you are short on time and just doing a quick search?
The same principle applies to coding, research and many other areas that have potential for the application of generative AI. By mindlessly automating things, people are forgetting automation are done based on scaling patterns. The machine does not care if the pattern is worth scaling just like the AI does not care if your question is worth answering. Giving up the task of answering questions to AI can lose us the crucial reflections we get from developing the answer one step at a time. This, by extension, hinders our ability to ask better question in the future.
In some cases, like when you are scaling a well-established labour intensive process, AI automation may be justified. But in many other, something a quick Google search or documentation reading can answer, the scale of the problem is simply not worth the devolution in your thinking.
I think the key at the end of the day is to exercise restraint. Before typing your question into the chat bot ask yourself these questions:
Is the time-saved I am getting more than 3-5 minutes?
Is the task something I don’t enjoy doing and gain/learn nothing from doing?
Is the use of AI going to help me produce results that are significantly better or more efficient compare to a clean human-oriented workflow (e.g. a simpler algorithm if you are a programmer)?
Are the results produced by the AI something I can easily validate?
If your answer to all of this is a resounding yes, then by all means, use AI. But if you even have an inkling of doubt, try doing it yourself first. Trust me, you will be surprised by how much you can do.
This article is written and edited without the use of AI (except as the subject of the various experiments presented).